Toward Textual Transform Coding
Context and Motivation
Increasingly, there is a need to store and communicate voluminous data such as 3D point cloud and multi-sensor data.
Are compression and streaming technologies approaching a rate-distortion-complexity Pareto front or not?
- cf) Pareto front is a curve (or surface) that illustrates the optimal trade-offs.
What would Shannon do? It is suggested that to match the predictive capabilities of humans, English text should be compressible to about 1.3 bits per character.
The author wanted to understand from humans what might be achievable in the context of multimedia data compression once:
- our algorithmic models catch up to those in our brains
- our codebooks/encoding/decoding make good use of humanity’s publicly available “side information”
- we tailor the reconstructions to what humans actually care about
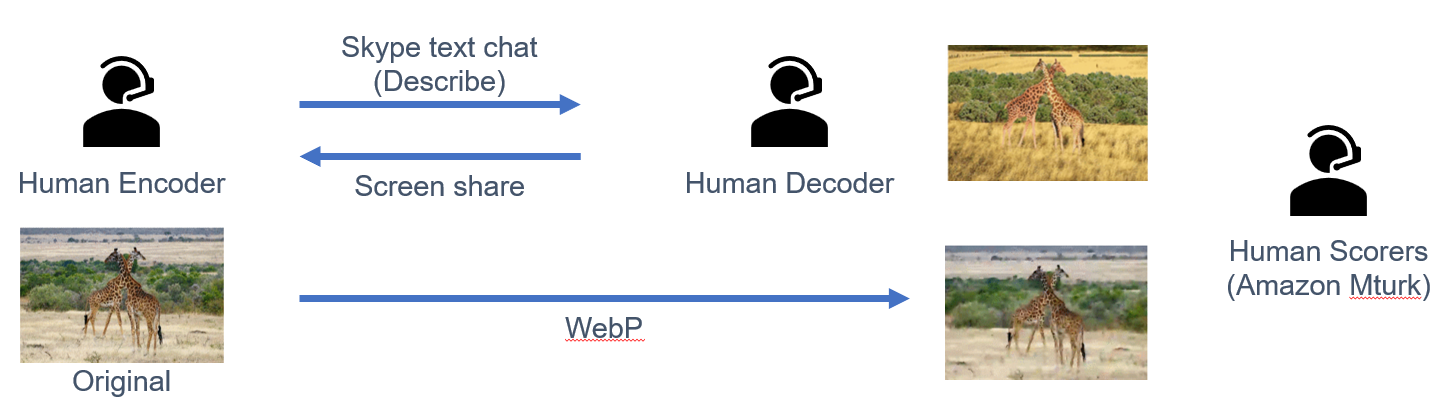
Human Compression System (2018)
Human Encoder was given a photo they hadn’t previously seen and that was not available online.
Human Compressors achieved higher quality than WebP confined to a similar bit rate on most image types.
SHTEM (2019~)
- Chau et al., “Building a Human-Centric Lossy Compressor for Facial Images,” The Informaticists Journal for High Schoolers 2019
- Gleaning insight into the potential for better facial image compression - From the way in which a police sketch artist creates an image.
- Bhown et al., “Humans are Still the Best Lossy Image Compressors,” DCC 2021
- Eliminated the human at the decoder while reducing the bit rate by another order of magnitude without compromising human satisfaction.
- Human encoder writes the Python code by itself so that the computer can understand and generate images.

- Prabhakar et al. research that communicates only the main points of the cast in the early stages of Covid-19 to enable real-time performances. (heeded by NVIDIA)
- In teleconferencing, such as ZOOM, audio is the main information that remains theoretically after learning people and backgrounds (Tandon et al.)
- Extract text from audio, synthesize mouth shape, etc. according to text, and compress it more than three times
- Pergament et al. use human input to teach a small deep net to anticipate regions of importance in a video, guiding the bit rate allocation

It is evaluated that “human language” has potential compared to existing compression methods.
Meanwhile, NLP and ML have been progressing dramatically
Quest for a New Transform
Most widely used information processing technologies are transform based.
- Transform – Process in the transform domain – Inverse transform
Four characteristics of Effective Transforms
- Coefficients in the transform domain correspond to meaningful elements
- Biologically, physically, perceptually, or conceptually
- Sparsity of and simple relationships between transform coefficients
- Uncorrelated, independent, etc.
- Smoothness of the forward and inverse transforms with respect to relevant
- Two similar inputs remain similar in the transform
- Low complexity of both the forward/inverse transform FFT is the most celebrated example of an effective transform.
Like the frequencies in FFT, new transform is Words-centric.
A Textual Transform
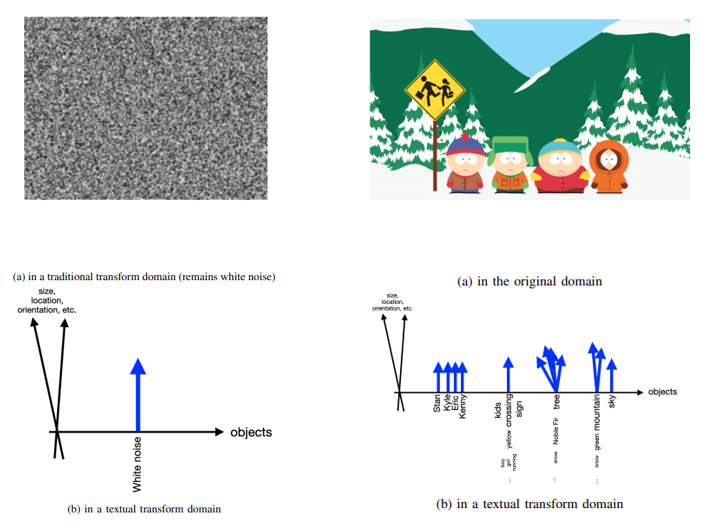
Moving from the qualitative to the concrete, a possible version of a lossy representation of an image in a transform domain would comprise the following elements.
- L(cognitive load): Description of how many objects
- And list of what they are (one word each)
- R(physical resolution): their sizes, locations, orientations
- W(textual resolution): words of description for each and how they relate Different choices of (L,R,W) correspond to different bit rates and description quality levels.
An extreme version of this idea
Encoding and Decoding are each of standalone value:
- The encoding being a readable textual summary of the data
- The decoder being a generator in the original data domain
With the implementable with existing technologies (DALL-E2), the compression rate can be made ludicrously low.
The number of bits required for Textual expression scale with the amount of nuances in the story of the picture, NOT the pixels, resolution.