ToDMA - Large Model-Driven Token-Domain Multiple Access for Semantic Coomunications
본 논문은 2025년 2월 컨퍼런스 논문 공개 (IEEE INFOCOM) / 2025년 5월 저널 버전 arXiv에 공개한 논문으로, Token Communications 프레임워크를 제안한 글과 같은 연구팀에서 나온 논문입니다.
앞서 제시한 TokCom의 네 가지 시나리오 중 Multiple Access에 집중한 논문으로, 보통 주파수 영역에서의 Orthogonality를 사용하는 기존 OFDMA 등과 달리 의미적인 직교성을 활용해보자는 약간은 추상적인 아이디어인 Semantic Orthogonality를 강조했으며, 이 직교성을 MLLM이 해소할 수 있다는 아이디어에서 출발했습니다.
간단히 요약하자면, 송신 측에서 Sparse한 행렬 여러 기기의 코드북 인덱스를 전송하면 수신 측에서는 Compressed Sensing을 통해 각 기기에서 보낸 정보를 감지하고, 이 감지한 정보가 각각 어느 기기에서 왔는지는 MLLM이 문맥을 통해 추정한다는 아이디어의 논문입니다.dfdf
Abstract
- Tx: Source Signal을 토큰화(Tokenization)하고 각 토큰을 Codeword로 Modulate한다.
- Rx
- active token과 해당하는 CSI를 감지하기 위해 먼저 compressed sensing을 실시한다.
- 다양한 타임 슬롯들 사이에 CSI를 통해 source token sequence를 복원해낸다.
- Token collision이 일어난 경우
- 할당되지 않은 활성화 토큰들이 생기고, 복원한 sequence에 빈 칸이 생긴다.
- 이 때 문맥을 활용해 pre-trained MLLM으로 Masked token을 예측하여 충돌을 완화한다.
1. Introduction
- token: 모델에서 정보 처리의 단위. 모달리티와 무관하게 패턴, 문맥, 관계 등을 담고 있는 discrete한 단위. BERT, VQ-VAE, MaskGIT, GPT 등의 토크나이저/pretrained GenAI를 소개하고 있다.
- What is Token Communication? 트랜스포머의 토큰을 통신의 기본 단위로 사용.
- TokCom 자체가 JSCC 전략으로 고려될 수 있음. 수신기는 입력 시퀀스를 복원하기 위해 여러 모달리티에 거친 중복성에 대한 statistical knowledge를 활용한다.
- ToDMA
- 토큰들 사이에 semantic-orthogonality를 도입.
- The cat jumped over the fence & Books provide inspiration 이라는 문장의 토큰들은 뒤섞여있더라도 MLLM이 다시 두 개의 문장으로 분리해낼 수 있다.
- 그러나 she likes to read, he dislikes to read 등과 같이 의미는 반대여도 분리되지 않는 경우가 생길 수 있으므로 트랜스포머 기반 토큰의 장점을 활용하는 practical non-orthogonal multiple access scheme을 제안한다.
2. Related Work
GenAI Meets SemCom
- GenAI for Source Coding
- GenAI for JSCC
Evolution of Multiple Access in 6G
- 산발적으로 짧은 패킷을 보내는 massive uncoordinated 단말들에 대해 NOMA와 GFRA가 주요 접근으로 고려된다.
- GFRA (Grant-Free Random Access): Base Station으로부터 비콘 신호를 받은 후 각 기기들이 동일한 RB에 unique preamble 전송. 이후 기지국이 각 기기의 활성 상태 감지, 채널 추정, 데이터 추정 진행
- 더 많은 숫자의 기기를 수용하기 위해 UMA - unsourced massive access가 제안됨. shared preamble codebook 에서 본인에 해당하는 코드워드를 골라서 보내고, 기지국은 사용자의 신원 정보는 아예 무시하고 코드워드를 해독하는 데에만 집중한다. 사용자에 대한 정보는 더 상위 레이어에서 해소된다는 아이디어.
- 같은 자원에 많은 기기들이 접속하는 경우, Compressed Sensing 기술을 도입하여 해소
- Compressed Sensing: 사용자가 보내는 정보가 sparse하다는 조건을 통해, 하나의 신호로부터 n명이 보낸 신호를 분리해낸다. underdetermine 문제이지만 여러 해 중 가장 sparse한 해를 찾아내는 것. L1-minimization과 같은 최적화 문제를 통해 해결 가능
- 최근 DeepJSCC와 NOMA를 결합한 연구가 활발히 이루어지고 있다.
3. Contributions
ToDMA Framework
pre-defined codebook을 통해 modulation한 시퀀스를 전송. 여러 개의 기기가 겹치게 전송 가능
수신기는 가능한 한 많은 토큰들을 탐지해내고, 문맥 및 Semantic Orthogonality를 활용하여 각각의 소스별로 재조립한다.
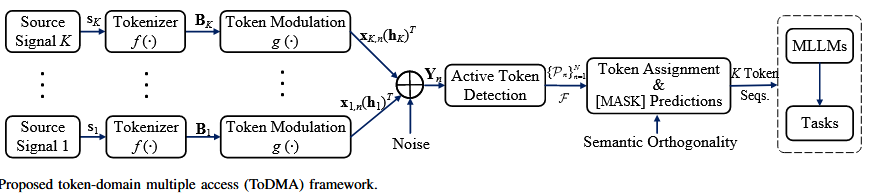
Three-step receiver architecture
- active token detection
- token activation의 희소성을 활용하여 active token set & corresponding CSI 를 compressed sensing 기반 알고리즘을 제안하여 결정한다.
- token assignment
- 각 기기의 CSI가 여러 time slot에 거쳐 유일하게 유지된다고 할 때 active token을 각 기기에 할당하기 위해 CSI를 그룹핑
- masked token prediction
- token collision으로 인해 몇몇 토큰들이 기기에 할당되지 못한 경우 문맥과 semantic orthogonallity를 활용하여 양방향 트랜스포머로 masked 토큰 예측
Communication/Computational efficiency
- Orthogonal tokcom에 비해 신호 재건 성능을 유지하며 4배 이상 높은 통신 효율 달성(실험으로).
- 수신기의 복잡성은 기지국의 안테나 수 및 기기 수에 linearly 비례. ToDMA는 특히 대규모 통신 시나리오와 massive MIMO 기지국들에 더욱 적합하다 (왜????)
- 기지국의 안테나 수가 늘어남에 따라 token detection error는 기하급수적으로 줄어든다.
4. Proposed ToDMA Framework
Transmitter Design
$K_T$ single antenna devices
$K (\ll K_T)$ active devices (주어진 시간에 보낼 데이터 있는 기기 수)
$M$ antennas Base Station
$\mathbf s_k$ denote the source signal of the $k$-th active device
- Tokenization
- 토크나이저는 원본 $\mathbf s_k$를 작은 조각들로 나눈다.
- $f(\cdot), Q$: 토크나이저와 token codebook의 크기를 의미
- $\mathbf B_k = f(\mathbf s_k) \in {0,1}^{Q\times N}$
- $\mathbf B_k$의 n-th column $b_{k,n}$은 각 토큰. (one-hot vector이다)
- 일반성을 잃지 않고 토큰 시퀀스의 길이 $N$은 모든 기기에서 동일하다고 가정
- Token Modulation
- 모든 기기에서 동일한 토크나이저 사용한다고 가정.
- $\mathbf{U} \in \mathbb C^{L\times Q}$ : multiple access를 위한 공통 modulation codebook
- $L$은 각 codeword의 길이
- 단순화를 위해 modulation codebook의 각 요소는 $\mathcal {CN}$에서 추출한다고 가정
- $\mathbf X_k=g(\mathbf B_k)=\mathbf{UB}_k \in \mathbb C^{L\times N}$
- $g(\cdot)$ represent the token modulation process
- $\mathbf X_k$의 n-th column $\mathbf x_{k,n}=\mathbf{U\cdot b}_{k,n} \in \mathbb C^{L\times N}$
- 공통 modulation codebook을 적용함으로써 대량의 장치에서 (조정되지 않은) 임의의 액세스를 지원하여 액세스 대기 시간 줄이며 구현 단순화한다.
- 기본 통신 단위를 전통적인 비트가 아닌 시맨틱 토큰으로 재정의하여 수신기가 transformer 기반 토큰 처리 및 MLLM과의 통합을 활용할 수 있도록 한다.
Multiple Access Signal Model
미래 6G 네트워크를 위한 일반적인 massive comm 시나리오
- BS는 많은 숫자의 uncoordinated 기기들을 수신한다.
- BS가 주기적으로 beacon 신호를 broadcast한다
- 단말기가 보낼 데이터가 있는 경우 active 상태로 전환하며 BS는 개별 단말의 active 여부를 모른다.
- 비콘 신호를 받은 경우 active device는 즉시 MAC을 통해 데이터를 전송한다.
- $K$ active devices는 동일한 $N$개의 통신 자원을 사용한다.
- 예를 들면 각각 $L$개의 심볼로 구성된 $N$개의 타임슬롯
- Receiver는 $n$-th 타임 슬롯에서 여러 신호가 overlapped된 신호 $\mathbf Y_n \in \mathbb C^{L\times M}$을 수신한다.
- $\mathbf Y_n = \sum_{k\in [K]}\mathbf x_{k,n}(\mathbf h_k)^T+\mathbf Z_n = \mathbf U\sum_{k\in [K]}\mathbf b_{k,n}(\mathbf h_k)^T+\mathbf Z_n = \mathbf{UH}_n+\mathbf Z_n$
- $\mathbf h_k \in \mathbb C^M$: $k$-th 단말기와 BS 사이의 채널 벡터
- Rayleigh fading channel: 각각의 채널 벡터는 complex gaussian distribution에서 랜덤하게 샘플.
- 각 타임 슬롯에서는 일정하게 유지됨
- $\mathbf Z_n$ follow i.i.d complex gaussian distributions w/ 평균 0 분산 $\sigma^2$
- $\mathbf h_k \in \mathbb C^M$: $k$-th 단말기와 BS 사이의 채널 벡터
- $\mathbf Y_n = \sum_{k\in [K]}\mathbf x_{k,n}(\mathbf h_k)^T+\mathbf Z_n = \mathbf U\sum_{k\in [K]}\mathbf b_{k,n}(\mathbf h_k)^T+\mathbf Z_n = \mathbf{UH}_n+\mathbf Z_n$
- Sparsity: 토큰 코드북의 크기는 active devices의 수보다 훨씬 크다고 가정한다.
- $\mathbf b_{k,n}$은 one-hot 벡터이므로 $\mathbf H_n$의 row sparsity가 보장된다.
- $K$개의 기기들이 모두 다른 토큰을 보냈다면 token collision이 일어나지 않는다.
Problem Formulation
$K$개의 기기가 보낸 token sequences를 복원해내기 위해 3단계의 receiver architecture를 제안한다.
- Active Token Detection
- 각 타임 슬롯 n마다 다음과 같이 subproblem formulate
- supp{}: support, 지지 집합 - 정의역을 유효한 범위로 축소. 즉 f(x)가 값을 가지지 않는 부분을 취급하지 않겠다는 뜻. $\mathrm{supp}(f)={x|f(x)\neq0}$ 한마디로 row sparsity 조건!
- 이 때 $\mathbf H_n$의 non-zero rows의 집합을 $\mathcal P_n$이라고 하자. 즉, 이 집합은 n-th 타임 슬롯에 전송된 토큰인 active tokens의 set을 의미
- 이 때 estimated equivalent channel vector는 아래와 같이 표현할 수 있다.
- $L\ll Q$이기 때문에 위의 최적화 문제는 어려운 underdetermined problem이 된다.
- Token Assignment
각 타임 슬롯에 추정된 토큰들은 해당하는 devices에 할당된다. 이 문제는 다음과 같다
\[\min_{\{{\alpha_{k,n}}\}^{K,N}_{k=1,n=1}} \sum^{K}_{k=1}\sum^{N}_{n=1}\mathbf 1\{\alpha_{k,n}\neq\alpha^*_{k,n}\} \\ \mathrm {s.t.} \ \ \alpha_{k,n} \in \hat{\mathcal P}_n, \forall n,k\]- 이 때 ground truth $\alpha^*$은 unknown이므로 이 문제는 underdetermined된 large-scale combinatorial optimization task
equivalent channel vector를 활용하여 위 문제를 조금 더 tractable하게 reformulate하면
\[\min_{\{{\alpha_{k,n}}\}^{K,N}_{k=1,n=1}} \sum^{K}_{k=1}\sum^{N}_{n=1} ||\psi_n(\alpha_{k,n})-\mathbf h_k||_2 \\ \mathrm {s.t.} \ \ \alpha_{k,n} \in \hat{\mathcal P}_n, \forall n,k\]- 이 때에도 역시 실제 채널 벡터 $\mathbf h_k$는 unknown이기 때문에 복잡성이 높다.
- 이에 대한 해결책은 Section 5에서 제시하였다. (CS-based active token detection)
- Masked Token Prediction
- Token assignment까지 끝냈다면 k-th 기기의 추정된 토큰 $\hat{\mathbf B}_k$를 구할 수 있다.
- 각 토큰의 estimation confidence를 표현하기 위해 score matrix $\mathbf D \in \mathbb R^{K\times N}$을 정의
- $[\mathbf D]_{k,n}$은 ${\hat{[\mathbf B]}_k} _{:,n}$ 벡터의 score이다.
- 점수 임계값보다 낮은 경우에는 토큰을 [Masked]로 표시한다.
- 이제 전체 신호의 의미, 문맥을 통해 masked tokens를 예측한다. 이 때 masked token은 주로 1,2번 task에서 최적화 문제를 풀 때 collision이나 error가 발생해서 생긴다
- Section 6에서 어떻게 이 점수를 찾는지, 그리고 예측하는지 자세히 다룬다.
5. Proposed CS-based Active Token Detection Scheme
수신된 신호로부터 어떤 토큰들이 활성화되어 전송되었는지 감지하고 해당 토큰들의 CSI를 추정한다. 측정값 L이 토큰 코드북 크기 Q보다 훨씬 작기 때문에 해결하기 매우 어려운 문제로, CS 기법과 AMP 알고리즘을 사용한다.
참고사항: 해당 section은 하나의 타임 슬롯에 대해서만 다루기 때문에 $n$을 생략하여 표기
Priliminary
우리는 posterior mean $\hat h_{q,m}$을 구하고 싶다.
\[\hat h_{q,m}=\int h_{q,m}p(h_{q,m}|Y)dh_{q,m} \ \forall q,m\]- q,m에 대해 구하고 싶으므로 전체 H의 분포에서 h_q,m을 제외한 나머지를 적분하면 된다. 즉 marginal posterior distribution 구하면 $p(h_{q,m}\vert Y)=$ $\int p(H\vert Y)dH_{\backslash q,m}$ 이 된다.
- 이후 베이즈 정리로 likelihood 및 prior-distribution으로 나눈 후 likelihood는 가우시안 분포에 대해 잡음으로 추정하면 되고 prior 분포는 sparsity ratio $\gamma_q$에 따라 $1-\gamma$의 확률로 0, $\gamma$의 확률로 레일리 분포 따르게 된다
- 자세한 내용은 굿노트 참조
AMP-Based Posterior Mean Estimation
marginal posterior probabilities $p(h_{q,m}\vert Y)=$ $\int p(H\vert Y)dH_{\backslash q,m}$ 을 계산하는 것은 어렵다. 특히 large signal dim $Q$에서는 더욱 그렇다.
이에 AMP 알고리즘을 도입하여 사후확률분포를 낮은 계산 복잡도로 근사한다.
6. Proposed Token Assignment and Masked Token Predeiction Schemes
같은 기기에서는 CSI가 고유하게 여러 타임 슬롯에 걸쳐 유사할 것이라는 가정으로 채널끼리 K-means++ clustering해서 여러 토큰들을 클러스터링하여 대략적인 토큰 할당을 먼저 한다. 이후 점수 D를 계산한 후 점수 낮은 애들은 잘못됐다고 판단한 후 이런 애들을 후보로 하여 트랜스포머 기반 예측을 한다.
7. Algorithm

계산 복잡도
- AMP-based token detection $\mathcal O(T_0NLQM)$
- Clustering alg in token assignment $\mathcal O(T_cKNM)$
- Transformer-based prediction (pre-trained BERT) $\mathcal O(KN^2H)$
최종 복잡도 $\mathcal O[T_0NLQM+K(T_cNM+N^2H)]$