Token Communications - A Large Model-Driven Framework for Cross-modal Context-aware Semantic Communications
이 논문은 2025년 Wireless Communications Letters에 Accept된 논문입니다. Token Communications라는 새로운 주제를 선점하려는 느낌의 논문이며, 기존 비트/패킷 단위의 통신이 아니라 트랜스포머의 처리 단위인 Token, 즉 임베딩을 단위로 하여 통신을 하자는 프레임워크를 제시하는 논문입니다.
크게 네 가지의 시나리오를 제시했으며, 이 중 MLLM을 통해 손실된 토큰을 문맥으로 복원하여(Generative Semantic Communication) 통신량을 줄일 수 있다는 것을 실험으로 제시하였습니다.
1. Introduction
GFM (Generative Foundation Models) / MLLMs (Multimodal LLM)들의 발전으로 인해 UltraLowRate 시맨틱 통신의 기회가 생겨났다.
이에, token communication TokCom을 제안한다.
tokenization을 통해 복잡한 멀티모달 정보들을 manageable, interpretable 부분들로 분해하여 SOTA 머신러닝 모델들을 transceiver로 사용할 수 있게 한다.
예시: A beach with palm [MASK] and clear blue water → LLM 활용 시맨틱 오류정정 메커니즘이 예측 → A beach with palm [trees] and clear blue water
Q1: What are the key potential opportunities and challenges of leveraging context via TokCom in GenSC?
Q2: 어떻게 SOTA 생성형/멀티모달 모델들을 시맨틱 통신 시스템 안에 결합하여 크로스-모달 문맥을 효과적으로 활용할 것인가?
Q3: What are the key principles and setups for efficient TokCom at various layers in future wireless networks? 미래 무선 통신의 다양한 Layer에서, 효과적으로 TokCom을 사용하기 위한 핵심 이론과 세팅은 무엇인가?
이 논문의 기여
- 새로운 TokCom 프레임워크 제시. 트랜스포머 기반 토큰 예측을 송수신기 파이프라인에 결합하여 cross-modal context-awareness 달성.
- token-level loss/error 완화 scheme 을 통해 재전송 없이도 주파수 효율 향상
- 이미지 생성 task에서 대역폭 효율을 70.8% 향상
2. Tokenization and Embedding of Various Data Modalities
Tokenizer가 전체 데이터를 표현할 수 있는 “토큰 임베딩 코드북”을 생성한다. (text:c4, image: LAION-5B)
이 논문의 실험: 각 토큰을 1024 token codebook을 통해 매칭시켜서 토큰 시퀀스로 변환하여 전송. 이 때 하나의 패킷에 16개의 토큰에 해당하는 코드북 인덱스 넣어서 전송하는 방식.
- Text Tokenization / Embedding
- 토큰화 모델들에 따라 한 토큰은 단어가 될 수도, 형태소가 될 수도, 문자가 될 수도 있다. 보편적으로는 subword로 나뉜다.
- e.g. WordPiece: “The supermarket is hosting a sale”→ “-The -super market -is -host ing -a -sale”
- 전통적으로는 Byte-Pair Encoding (BPE), WordPiece, unigram 등 fixed embeddings
- 최근엔 BERT / GPT 등 contextual embedding을 학습한다.
- Image/Video Tokenization / Embedding
- 보통 이미지를 fixed-size patches로 나눈 후 flattened, embedded 과정 거친다.
- VQ-VAE 에서는 각 임베딩들을 불연속적인 latent space로 인코딩한다.
- Audio
- 파형을 스펙토그램으로 변환하여 토큰화.
- 일반적으로 log Mel filterbanks같은 기술을 사용하여 주파수 기반 특징을 잡는다.
3. Tokens, Attention and Transformers
- Unidirectional: GPT에서 답변을 생성하듯 이전 토큰만 활용한다. Transmitter에서 다음 토큰이 예측하기 쉬운 경우 저전력 할당 등으로 활용한다
- Bidirectional: 비어 있는 mask를 예측한다. Receiver에서 손실된 토큰을 예측해내는데 사용한다.
4. TokCom: Opportunities and Challenges
- 기존 DeepJSCC와 달리 end-to-end 훈련 필요성이 없기 때문에 확장성과 적응성이 뛰어나다
- Ultra Low Rate 시맨틱 통신을 위해 다양한 모달리티가 통합된 토큰들을 활용한다.
- 높은 computational cost가 한계이다.
- cloud-edge-device collaborative로 해결 가능할 것이다.
5. Basic Token Communication Setups
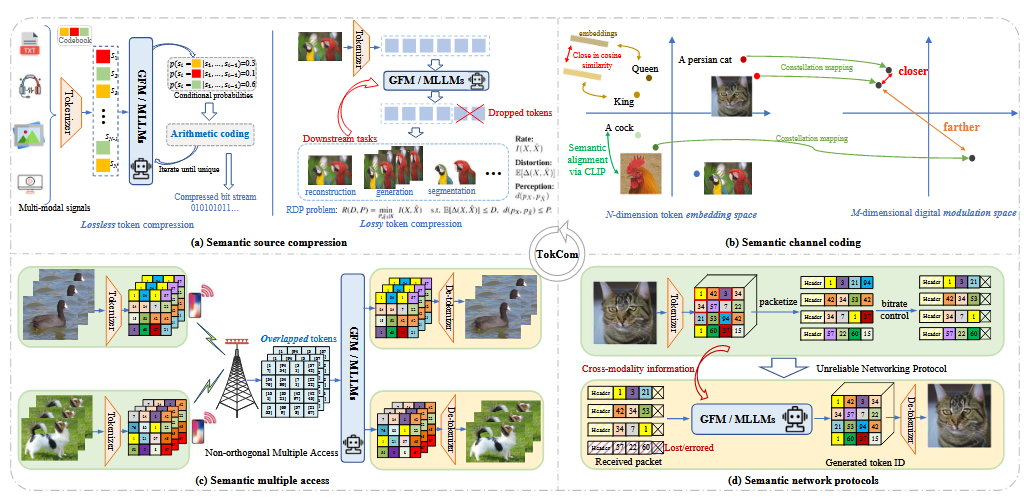
TokCom for semantic source compression
언어모델은 기본적으로 압축의 형태를 가진다. 다음 혹은 masked 토큰에 대한 정확한 예측 기반이기에.
SOTA GFM/MLLM이 문맥에 따라 토큰의 조건부 확률을 예측한다. predictability를 통해 다양한 모달리티를 압축. 논문 [10]에서는 언어로만 훈련된 모델이 효과적으로 이미지넷 패치들을 압축한다는 결과가 있다.
토큰화는 inherently하게 lossy compression이다.
rate-distortion-perception theory에 의해 성능 한계를 규정할 수 있다.
TokCom with semantic channel coding
채널 코딩과 modulation scheme을 다음 토큰 / masked 토큰의 predictability에 의해 정하기.
현재 무선 통신에서는 MCS가 채널 품질에 의해서만 정해진다. 톡컴에서는 MCS를 각 토큰 (혹은 토큰들의 블럭)마다, 채널 품질 + 토큰 predictability로 최적화한다.
- 다른 가능성: symbol mapping
- 토큰의 의미론적 유사성을 활용하여 token codebook → channel symbols 매핑을 최적화.
- 의미론적으로 유사할수록 가까운 constellation에 배치되어야 한다.
TokCom for Semantic multiple access
token domain에서의 Semantic-orthogonality를 활용하여,
여러 신호가 한 채널에 비직교로 뒤섞이는 등의 collision이 발생했을 때 GFM/MLLM이 semantic orthogonality을 활용하여 두 기기의 신호를 분리해낸다.
후속 논문 ToDMA에서 더 살펴볼 예정이다.
TokCom network protocols
- 각 토큰은 몇 비트를 활용하여 index만 보내진다. (토큰 코드북 활용)
- TokCom Packet은 패킷 사이즈에 따라 몇 개의 토큰을 포함한다.
- 리시버가 패킷 loss를 복원해냄으로써 UDP와 같은 less reliable protocol을 이용할 수 있다.
- 재전송 횟수를 효과적으로 줄이고, flow/congestion control의 부담을 경감
- MLLM을 활용해 less predictable token을 우선시하는 등 Context-aware Routing도 적용될 수 있다.
6. Case Study: Cross-Modality TokCom for Gen-Img SemCom
Setup
- Dataset
- ImageNet100: 256*256 픽셀 이미지들
- Channel
- Flat reyleigh fading channel
- Tx
- (언급되지는 않았으나) VQ-GAN 사용했을 것으로 예상됨 (후속 연구 ToDMA에서 사용)
- Each Tokenized into N=256 discrete tokens
- Each Packet containing 16 random tokens and token positions
- Codebook Size Q=1024 (10-bit binary sequence)
- rate-1/2 convolutioncal encoding w/ cycle redundancy
- Modulation scheme: 16-QAM
- Rx
- Soft Viterbi decoder
- Metric
- PER: packet error rate as a function of SNR
- T: avg num of packet retx (required for successful data reception)
- 1/(1-PER)
- TCE: token communication bandwith efficiency
- $\frac{h\times w}{T \times N \times \log_2(Q)}$
Proposed Cross-Modality TokCom Scheme
- TokCom w/ CMI: with cross-modality information
- 각 패킷은 한 번만 보내진다. (T=1)
- 에러가 발생한 패킷은 [MASK] 라는 특수 토큰으로 채워진다.
- 디코더는 이러한 mask 토큰을 MaskGIT이라는 pretrained bi-directional transformer를 통해 문맥 정보를 활용하여 순차적으로 예측한다.
- 구체적으로, 개별 채널을 통해 전송된 7bit의 이미지 라벨 텍스트 정보를 복원에 활용
- 대조군
- TokCom w/o CMI
- Conventional scheme: 각 에러 패킷을 재전송. ARQ의 오버헤드는 무시
7. Open Problem and Future Research Direction
- 효율적인 Tokenizer 디자인: semantic compression 성능에 큰 영향 미친다.
- BPE 는 종종 토큰들을 더 큰 토큰으로 병합하며 길이를 줄여서, 모델이 제한된 컨텍스트에서 더 많은 데이터를 처리할 수 있도록 하지만 코드북 크기가 증가하는 단점.
- 서로 다른 모달리티 사이의 효율적 unified tokenizer 설계가 또다른 도전이다.
- TokCom의 계산 복잡도와 collaborative inference
- 경량 모델과 대형 모델 사이의 collaborative device-edge-cloud inference가 디자인될 수 있다.
- TokCom Privacy and Security
- semantic payload는 추론 공격에 취약하다.
- TokCom을 위해 특별히 설계된 암호화 방법을 개발해야 한다.
본 논문을 인용한 논문들 (후속 연구)
- Generative Video Semantic Communication via Multimodal Semantic Fusion with Large Model
- 단순히 생성형 ai의 발전이 전송 효율을 높이는 통신에도 반영될 수 있다는 정도로 intro에서 언급
- Task-Adaptive Semantic Communications with Controllable Diffusion-based Data Regeneration
- Semantic Packet Aggregation for Token Communication via Genetic Beam Search
- 고정된 수의 그룹 내에서 패킷화를 위한 토큰 그룹화 최적화 알고리즘 제안
- SemPA-GBeam. (semantic packet aggregation w/ genetic beam search)
- 목표: maximize the avg token similarity (ATS) over erasure channels. erasure channel에서도 수신된 토큰들 간의 의미적 유사성을 최대한 높이도록 그룹화
- ToDMA(Token Domain Multiple Access) 논문
- 동일 저자팀의 논문 / Deniz Gunduz 교신저자